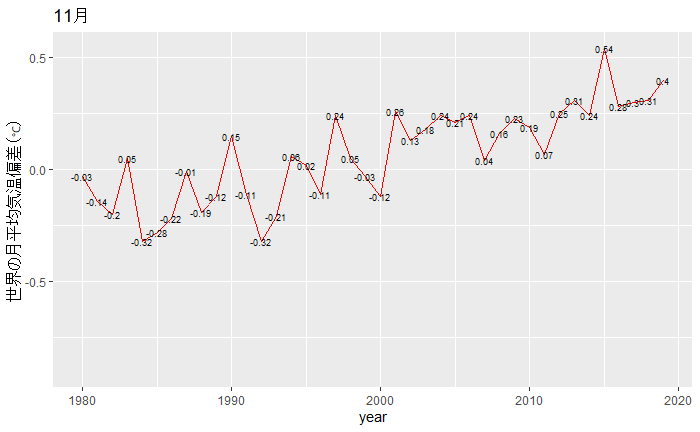
◆楽天市場の商品レビューのテキスト分析:「ワードクラウドの比較」や対応分析など、分析手順を一般化すればアンケートの自由回答分析が可能になります。:「リピート」購入者は、うどんや弁当にも?
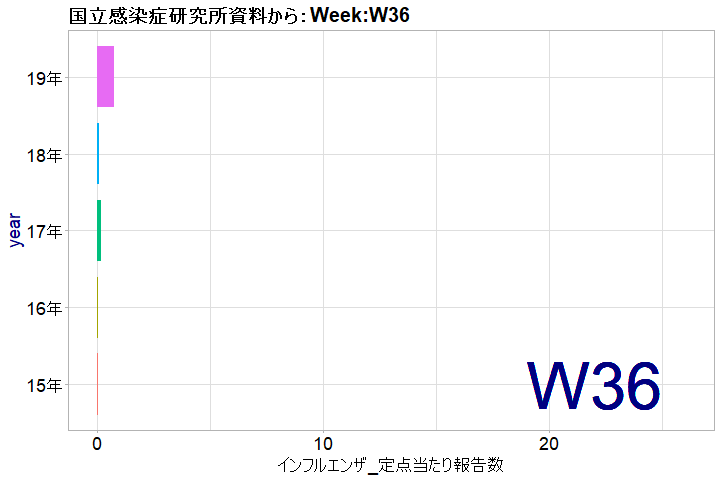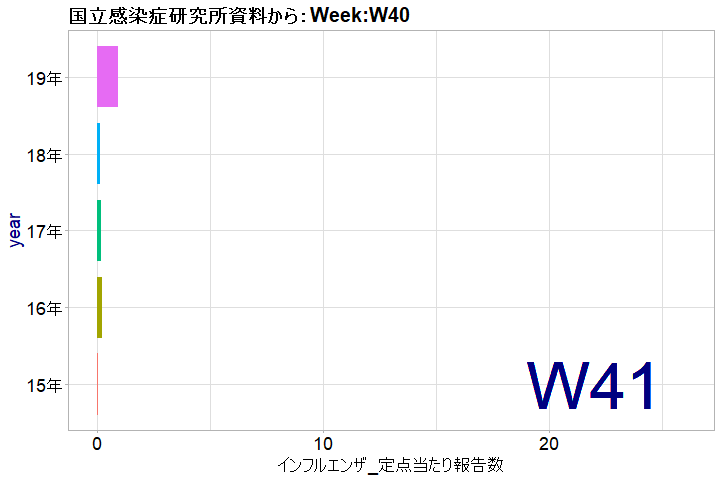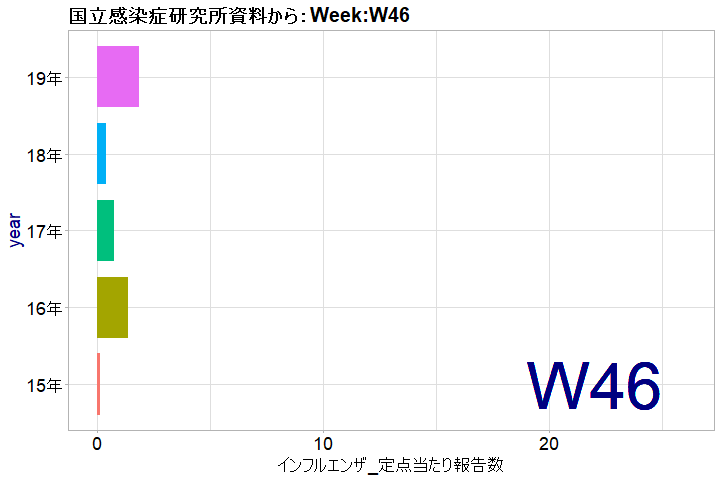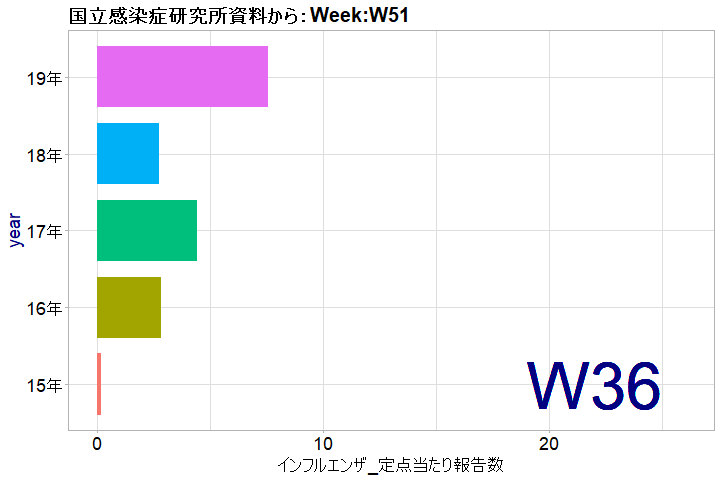
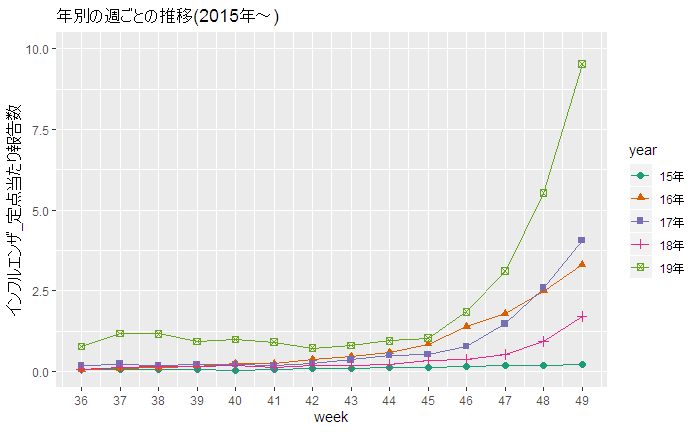
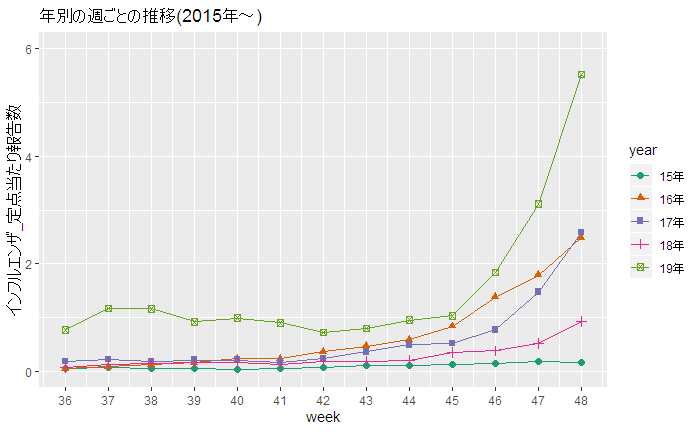
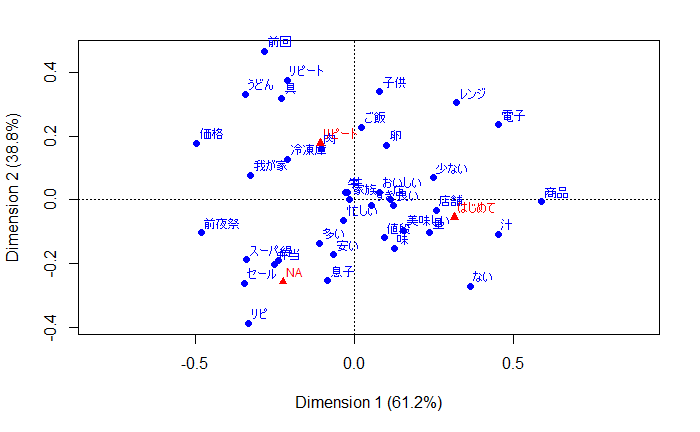
先日の「冷凍牛丼の具」のレビューのテキスト分析の続編です。関連記事:【ちょっと好奇心】「冷凍牛丼」はどのような時期に購入されているのでしょうか:「冷凍庫に常備していると重宝する冷凍牛丼」 以下の記事は、テキストの分析内容よりも、このような分析手順を「R」のコードで整備すれば、一般的なアンケートの自由回答分析もほぼ自動で処理可能になるのではないか、という観点からのものです。 「購入回数」別の「ワードクラウド」用に準備したテキストファイルをRMeCabの「docDF()」で処理すれば、対応分析(コレスポンデンス分析)もできます。 まず、単純な単語頻度分析ですが、「ワードクラウド」で可視化する場合に、レビュー以外の回答の情報や属性情報と組み合わせてみることが考えられます。 例えば、この商品の購入回数の情報には、下図の棒グラフのように「はじめて」「リピート」「NA(無回答)」というものがあります。 そこで、「はじめて」と「リピート」で自由回答の頻出語に違いが見られるかどうかをワードクラウドで見てみました。 ワードクラウドの結果を見ると、ほとんど同じような単語が見られ、あまり違いはなさそうです。 しかし、冒頭の対応分析の図で見ると「はじめて」「リピート」「NA」で、レビューに出現する単語の傾向に少し違いがあることがうかがえます。横軸方向の寄与度が大きいので、横軸方向で見るのが一番いいと思います。 「リピート」は、「前夜祭」「セール」「価格」といった単語の方向にあるので、「リピート」購入している人は、セールを活用してより安く購入している様子がうかがえます。 横軸での方向で、「リピート」と「NA」は同じ方向なので、「NA」の人には「リピート」の人が多いのかもしれません。 また、横軸での方向で、「うどん」「弁当」という単語が「リピート」側にあることから、「リピート」購入している人は、「うどん」「弁当」などへと用途を広げているのかもしれません。「用途拡大」の提案に成功すれば、「リピート」購入は増えるのではないでしょうか。 購入者側の視点からすると、冷凍牛丼の具に、「うどん」や「弁当」など、いろいろな食べ方があることを知るきっかけになるので、購入の際の参考になるかもしれません。 横軸で見て、「電子」「レンジ」という単語の方向に、「はじめて」が位置しているので、「はじめて」の人は「電子レンジ」で調理できることに関心を持って購入した人がいるのかもしれません。 「ワードクラウド」で目立っている単語は、対応分析の図の中心付近に位置しているようですが、対応分析図の中心に布置されるものは「特徴がない」ものになるので、「ワードクラウド」で違いがわからないのも無理はないと思います。 いずれ、単純な頻度分析だけではなく、「特徴語抽出」のようなことも試してみたいと思います。 なお、このような、分析方法は、年代別といった属性情報と組み合わせることも可能なので、一般的なアンケートの自由回答にも使えると思います。 <「購入回数」の回答><「購入回数」が「はじめて」の人の自由回答の単語の頻度分析><「購入回数」が「リピート」の人の自由回答の単語の頻度分析>対応分析用のデータから、「comparison.cloud(data[, 2:3])」で比較クラウドができました。----------------------------------------------------------------------<「R]のコード例(抜粋)> 「RMeCabFreq()」の分析対象のテキストを、自由回答以外の回答項目(今回の例では、「購入回数」の回答)で絞り込みます。df_r1 <- filter(df_r, usage3 == "はじめて")temp <- dplyr::select(df_r1,reviews)write.table(temp,"temp_r1.txt")temp_r1 <- RMeCabFreq("temp_r1.txt")temp_r1 <- subset(temp_r1, Info1 == "名詞" | Info1 == "形容詞")df_r2 <- filter(df_r, usage3 == "リピート")temp <- dplyr::select(df_r2,reviews)write.table(temp,"temp_r2.txt")temp_r2 <- RMeCabFreq("temp_r2.txt")temp_r2 <- subset(temp_r2, Info1 == "名詞" | Info1 == "形容詞") #「NA(無回答)」の自由回答を抽出する場合。df_r3 <- filter(df_r, is.na(usage3))temp <- dplyr::select(df_r3,reviews)write.table(temp,"temp_r3.txt")temp_r3 <- RMeCabFreq("temp_r3.txt")temp_r3 <- subset(temp_r3, Info1 == "名詞" | Info1 == "形容詞") 年代別で分析する際には、回答数の少ない年代もあるので、下記の例のように、年代のカテゴリーを統合しておく必要もあると思われます。その後は、「購入回数」の場合と同様に、変数「age1」で分析対象の自由回答を絞り込むことができます。df_r <- df_r %>% mutate(age1 = case_when( df_r$age %in% c("10代", "20代", "30代") ~ "30代以下", df_r$age %in% c("40代", "50代") ~ "40代~50代", df_r$age %in% c("60代", "70代以上") ~ "60代以上"))----------------------------------------------------------------------【期間限定】【送料無料】牛丼の具20パックセットすき家牛丼の具冷凍食品 【S8】価格:4560円(税別、送料別)(2019/12/5時点)楽天で購入Rによるテキストマイニング入門(第2版) [ 石田 基広 ]価格:2860円(税別、送料別)(2019/12/11時点)楽天で購入RMeCabパッケージの開発者の著書です。Rでテキストマイニングできるのは、石田先生のおかげです。------------------------------------------------------★おすすめの記事 ◆日本の月平均気温偏差(℃):月別の時系列データの分析:グーグルのデータポータルのダッシュボードによる、並べ替えができる表です◆インフルエンザの流行が始まったようです:今年は流行の始まりが早いようです◆今後、アマゾン・プライム・ビデオは「Edge」ブラウザで観ることにしました:動画配信サービスの「HD」画質と「HD 1080p」画質。回線速度によって決まるというけれど、それは本当でしょうか?◆Netflix:「ストレンジャー・シングス NG集」が公開されました:「Bloopers」とは「NG集」のことでした。◆Netflixの4半期決算報告で紹介されている作品は?:決算報告資料は、Netflixの話題作を探す一つの手段です◆Netflix (NFLX)の第3四半期決算発表で、NFLXの株価上昇:1株利益が予想を上回る:「ストレンジャー・シングス」効果?で有料会員数の増加数は前年同期を上回る◆Windowsパソコンで、Netflixを観る時に、Windows Sonic for HeadphonesやDolby Atmos for Headphonesをオンにする理由:「Amaze」トレーラーの録音データの分析から:Reasons to turn on Windows Sonic◆やっぱり、Windowsパソコンで、Netflixを観る時に、Windows Sonic for HeadphonesやDolby Atmos for Headphonesをオンにする理由:「Amaze」トレーラーの録音データの分析から(その2)◆How Windows Sonic looks like.:Windows Sonic for Headphonesの音声と2chステレオ音声の比較:7.1.2chテストトーンの比較で明らかになった違い:一目で違いがわかりました----------------------------------------------------------------------------------------------------------