|
|
|
|
2019.10.06
カテゴリ:データ分析
Dolby Atmosの「Amaze」トレーラーの録音データの分析をしてみました。
 Winsows10のパソコンで、Windows Sonic for Headphones、Dolby Atmos for Headphonesを「オン」にした場合と「オフ」にした場合のトレーラーの録音データの比較です。 Windows Sonic for Headphones、Dolby Atmos for Headphonesを「オン」にした場合の録音データの波形は振れ幅が大きく、迫力のある音声であることがわかります。耳にダメージを与えないように、音量を上げ過ぎないように注意する必要があります。 録音データの波形は、Windows Sonic for Headphones、Dolby Atmos for Headphonesを「オン」にすると、Netflixの5.1ch音声をより迫力ある音声で楽しめることを明らかに示しています。 図1:Windows Sonic for Headphonesを「オン」にして録音した場合 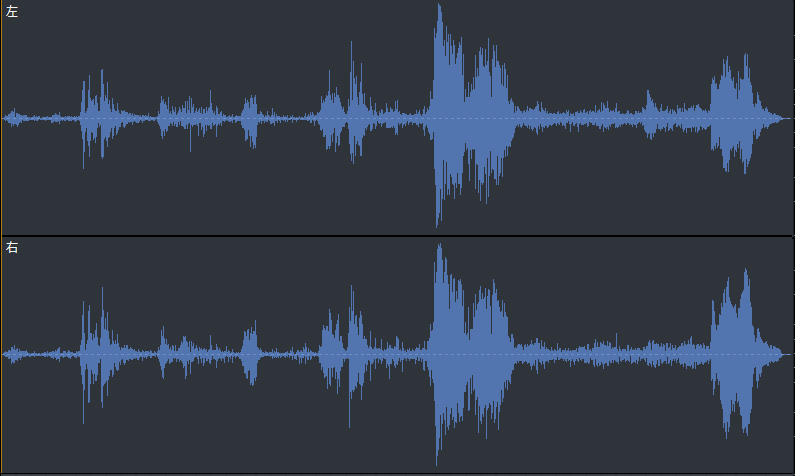 図2:Dolby Atmos for Headphonesを「オン」にして録音した場合  図3:立体音響を「オフ」にして録音した場合(ステレオモード再生) 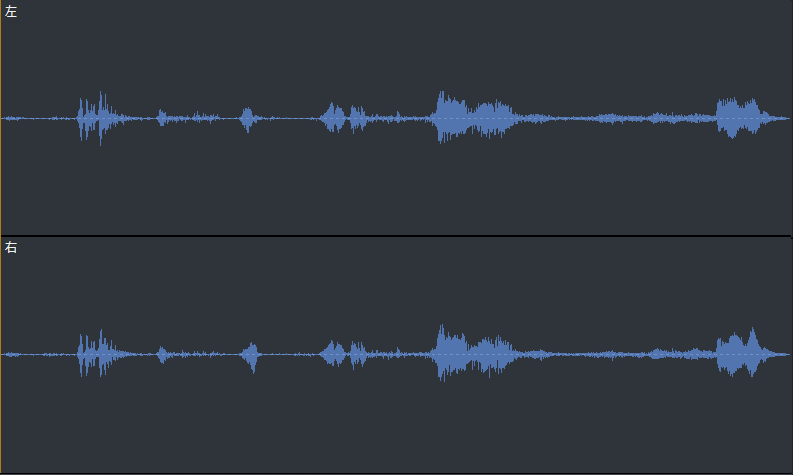 スペクトル解析の結果などのより詳細な情報やグラフは、「こちらの記事(Blogger の記事)」にあります。 <付録:録音データ分析用の「Rコード例」> 音声データの「R」での分析コードは、ネット上であまり見かけないので、自己流の拙いものですが、備忘録として記しておきます。「テストトーン」の分析用のコードをベースにしています。 最も注意を要したのは、「コード」以前に、分析対象区間を秒数で指定するので、録音データの尺をできるだけそろえることでした。 冒頭の不要な無音部分を手動でカットしたので、尺が合うようにするのに留意しました。 ----------------------------------------------- library("soundgen") library(seewave) library(tuneR) library(ggplot2) library(tidyr) library(dplyr) library(plyr) library(data.table) sctrans <- data.frame(Scene = c(1, 2, 3, 4, 5), SCNAME = c("Opening", "Woods", "Thunder", "Rain", "Ending")) wdat <- readWave("amaze_winsonic.wav") wdatL<-channel(wdat,"left") wdatR<-channel(wdat,"right") amaL1<-cutw(wdatL,from=0,to=11.5) amaL2<-cutw(wdatL,from=11.5,to=24) amaL3<-cutw(wdatL,from=24,to=39) amaL4<-cutw(wdatL,from=39,to=47) amaL5<-cutw(wdatL,from=47,to=58.5) amaR1<-cutw(wdatR,from=0,to=11.5) amaR2<-cutw(wdatR,from=11.5,to=24) amaR3<-cutw(wdatR,from=24,to=39) amaR4<-cutw(wdatR,from=39,to=47) amaR5<-cutw(wdatR,from=47,to=58.5) df_lr <- NULL i = 0 for(i in 1:5){ amal <- get(paste("amaL",i,sep="")) amaR <- get(paste("amaR",i,sep="")) d_l <- meanspec(amal, f = 48000,norm=FALSE,correction = "energy", flim = c(0, 20), col="blue") colnames(d_l) <- c("Frequency", "Left") d_r <- meanspec(amaR, f = 48000,norm=FALSE,correction = "energy", flim = c(0, 20), col="red") colnames(d_r) <- c("Frequency1", "Right") d_lr <- cbind(d_l,d_r) d_lr <- as.data.frame(d_lr) d_lr$Scene <- as.integer(i) d_lr$Sound_File <- as.character("WinSonic") df_lr <- rbind(df_lr,d_lr) } tail(df_lr) wdf_lr <- df_lr ddat <- readWave("amaze_dolby.wav") ddatL<-channel(ddat,"left") ddatR<-channel(ddat,"right") amaL1<-cutw(ddatL,from=0,to=11.5) amaL2<-cutw(ddatL,from=11.5,to=24) amaL3<-cutw(ddatL,from=24,to=39) amaL4<-cutw(ddatL,from=39,to=47) amaL5<-cutw(ddatL,from=47,to=58.5) amaR1<-cutw(ddatR,from=0,to=11.5) amaR2<-cutw(ddatR,from=11.5,to=24) amaR3<-cutw(ddatR,from=24,to=39) amaR4<-cutw(ddatR,from=39,to=47) amaR5<-cutw(ddatR,from=47,to=58.5) df_lr <- NULL i = 0 for(i in 1:5){ amal <- get(paste("amaL",i,sep="")) amaR <- get(paste("amaR",i,sep="")) d_l <- meanspec(amal, f = 48000,norm=FALSE,correction = "energy", flim = c(0, 20), col="blue") colnames(d_l) <- c("Frequency", "Left") d_r <- meanspec(amaR, f = 48000,norm=FALSE,correction = "energy", flim = c(0, 20), col="red") colnames(d_r) <- c("Frequency1", "Right") d_lr <- cbind(d_l,d_r) d_lr <- as.data.frame(d_lr) d_lr$Scene <- as.integer(i) d_lr$Sound_File <- as.character("DolbyAtmos") df_lr <- rbind(df_lr,d_lr) } tail(df_lr) ddf_lr <- df_lr sdat <- readWave("amzestmodestereo.wav") sdatL<-channel(sdat,"left") sdatR<-channel(sdat,"right") amaL1<-cutw(sdatL,from=0,to=11.5) amaL2<-cutw(sdatL,from=11.5,to=24) amaL3<-cutw(sdatL,from=24,to=39) amaL4<-cutw(sdatL,from=39,to=47) amaL5<-cutw(sdatL,from=47,to=58.5) amaR1<-cutw(sdatR,from=0,to=11.5) amaR2<-cutw(sdatR,from=11.5,to=24) amaR3<-cutw(sdatR,from=24,to=39) amaR4<-cutw(sdatR,from=39,to=47) amaR5<-cutw(sdatR,from=47,to=58.5) df_lr <- NULL i=0 for(i in 1:5){ amal <- get(paste("amaL",i,sep="")) amaR <- get(paste("amaR",i,sep="")) d_l <- meanspec(amal,f = 48000,norm=FALSE,correction = "energy", flim = c(0, 20), col="blue") colnames(d_l) <- c("Frequency", "Left") d_r <- meanspec(amaR,f = 48000,norm=FALSE,correction = "energy", flim = c(0, 20), col="red") colnames(d_r) <- c("Frequency1", "Right") d_lr <- cbind(d_l,d_r) d_lr <- as.data.frame(d_lr) d_lr$Scene <- as.integer(i) d_lr$Sound_File <- as.character("Stereo") df_lr <- rbind(df_lr,d_lr) } tail(df_lr) sdf_lr <- df_lr swddf_lr <- rbind(wdf_lr,ddf_lr,sdf_lr) tail(swddf_lr) for(i in 1:5){ td_lr <-select(swddf_lr,Frequency,Left,Right,Sound_File,Scene) %>% filter(Scene == i) swddf_lr1 <- join(td_lr,sctrans,by="Scene") swddf_lr1$SCNAME <-as.character(swddf_lr1$SCNAME) g <- ggplot(data = swddf_lr1) + geom_line(aes(x=Frequency,y=Left,group=Sound_File, colour=Sound_File)) + xlim(0,20) + labs(x="Frequency(kHz)",y="Energy(log2)") + labs(title="Left Speaker") + scale_y_continuous(trans = 'log2') g1 <- g + facet_wrap(~SCNAME) ggsave(file=paste0("aml",i,".png"),plot(g1),dpi = 200, width = 7.2, height = 4.8) print(g1) g <- ggplot(data = swddf_lr1) + geom_line(aes(x=Frequency,y=Right,group=Sound_File, colour=Sound_File)) + xlim(0,20) + labs(x="Frequency(kHz)",y="Energy(log2)") + labs(title="Right Speaker") + scale_y_continuous(trans = 'log2') g1 <- g + facet_wrap(~SCNAME) ggsave(file=paste0("amr",i,".png"),plot(g1),dpi = 200, width = 7.2, height = 4.8) print(g1) } swddf_lrw <- select(swddf_lr,Frequency,Left,Right,Sound_File,Scene) %>% filter(Sound_File == "WinSonic") for(i in 1:5){ td_lr <-select(swddf_lr,Frequency,Left,Right,Sound_File,Scene) %>% filter(Scene == i) swddf_lrw <- join(td_lr,sctrans,by="Scene") swddf_lrw$SCNAME <-as.character(swddf_lrw$SCNAME) glrw <- ggplot(swddf_lrw, aes(x=Frequency)) + geom_line(aes(y = Left,color="Left")) glrw <- glrw + geom_line(aes(y = Right,color="Right")) glrw <- glrw + scale_color_manual(values = c("blue","red"))+ggtitle("WinSonic") + labs(x="Frequency(kHz)",y="Energy") + labs(color = "Channel")+ scale_y_continuous(trans = 'log10') + facet_wrap(~SCNAME) plot(glrw) } -------------------------------------------------------------  お気に入りの記事を「いいね!」で応援しよう
Last updated
2020.05.15 18:03:54
コメント(0) | コメントを書く
[データ分析] カテゴリの最新記事
|
|
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/18c0e353.3594f537.18c0e354.1223c91d/?me_id=1206032&item_id=11284735&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fjism%2Fcabinet%2F0431%2F4580476280015.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fjism%2Fcabinet%2F0431%2F4580476280015.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")




