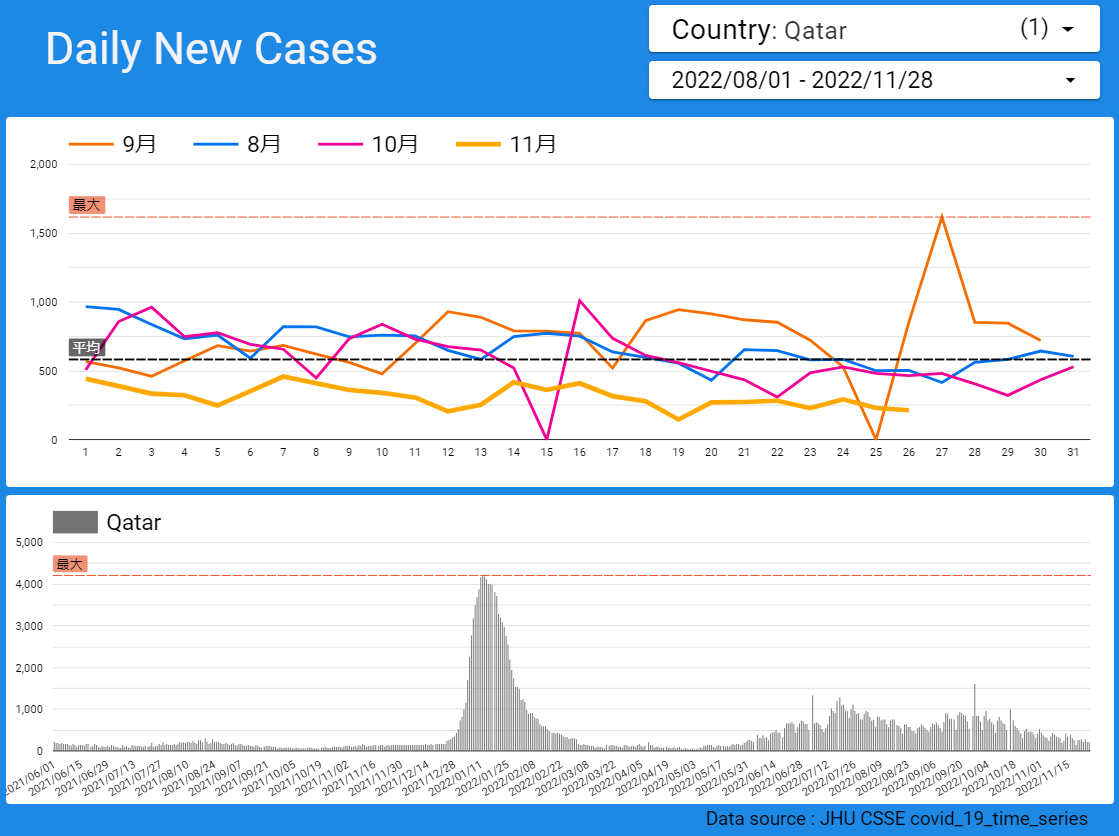
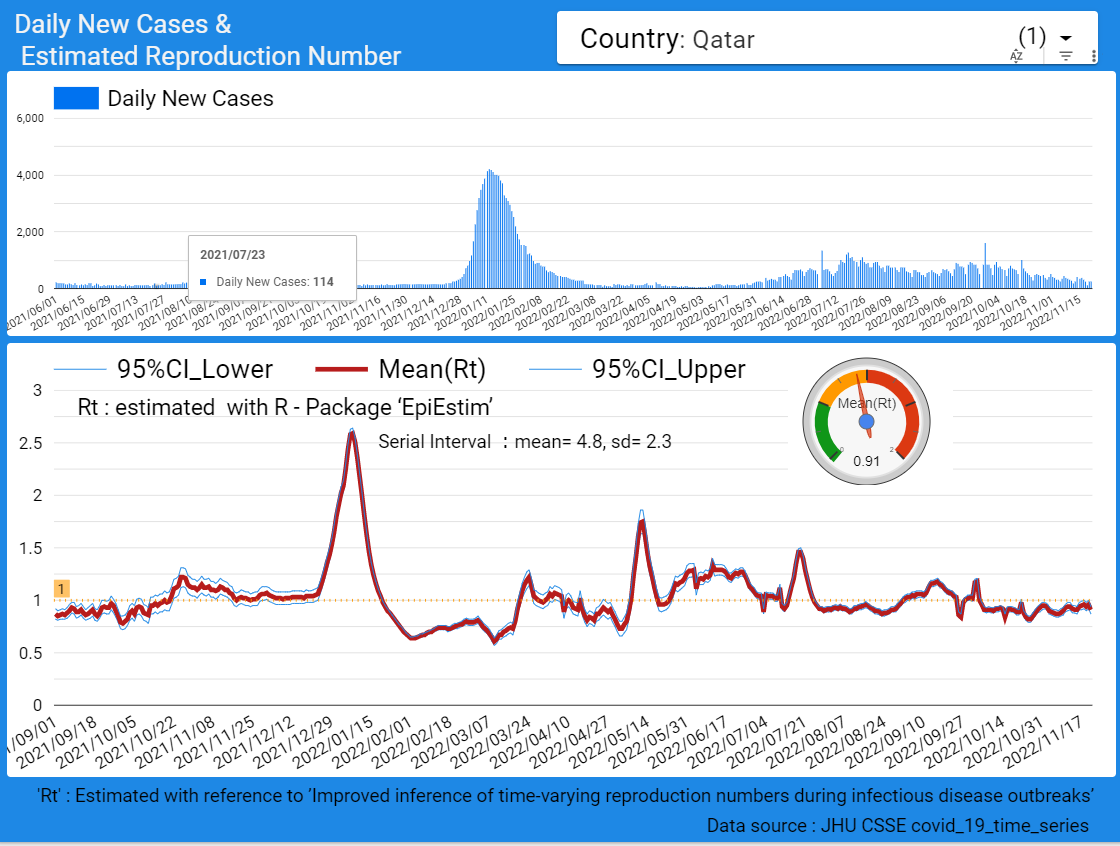
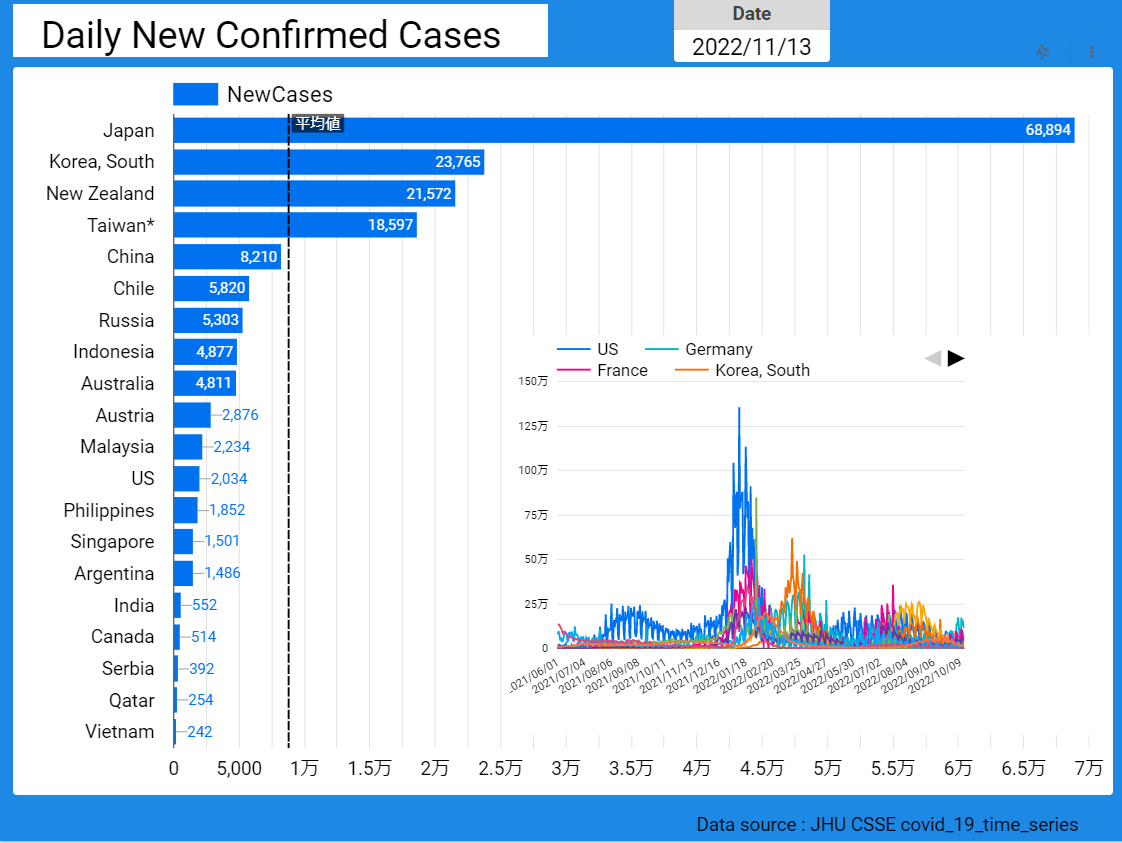
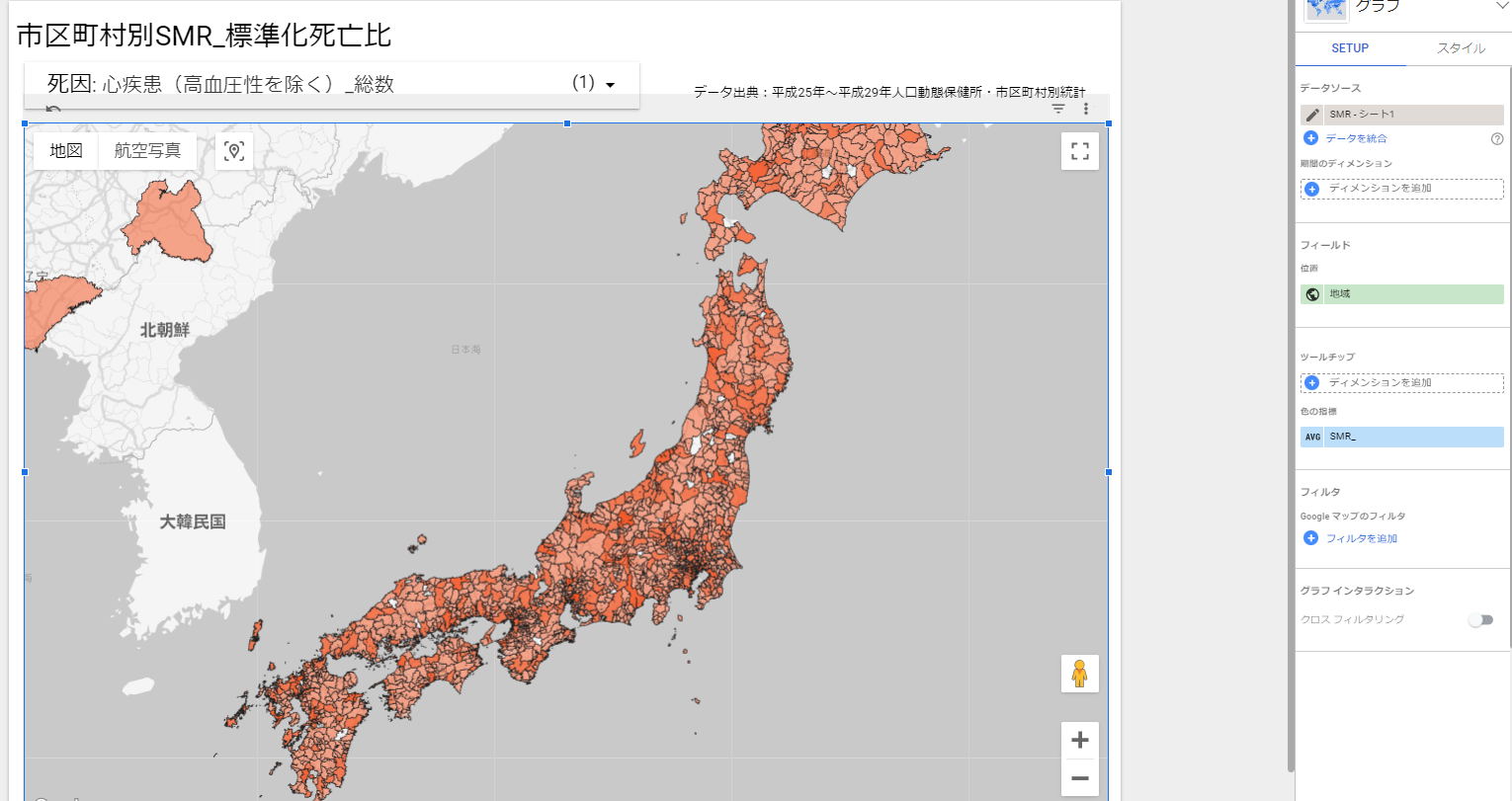
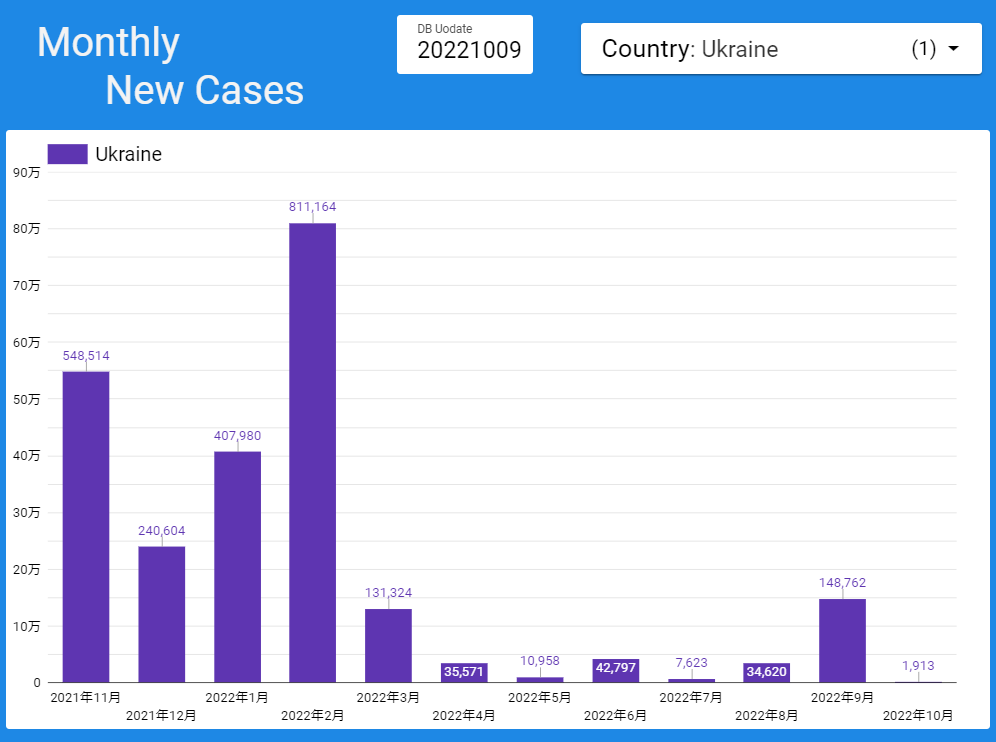
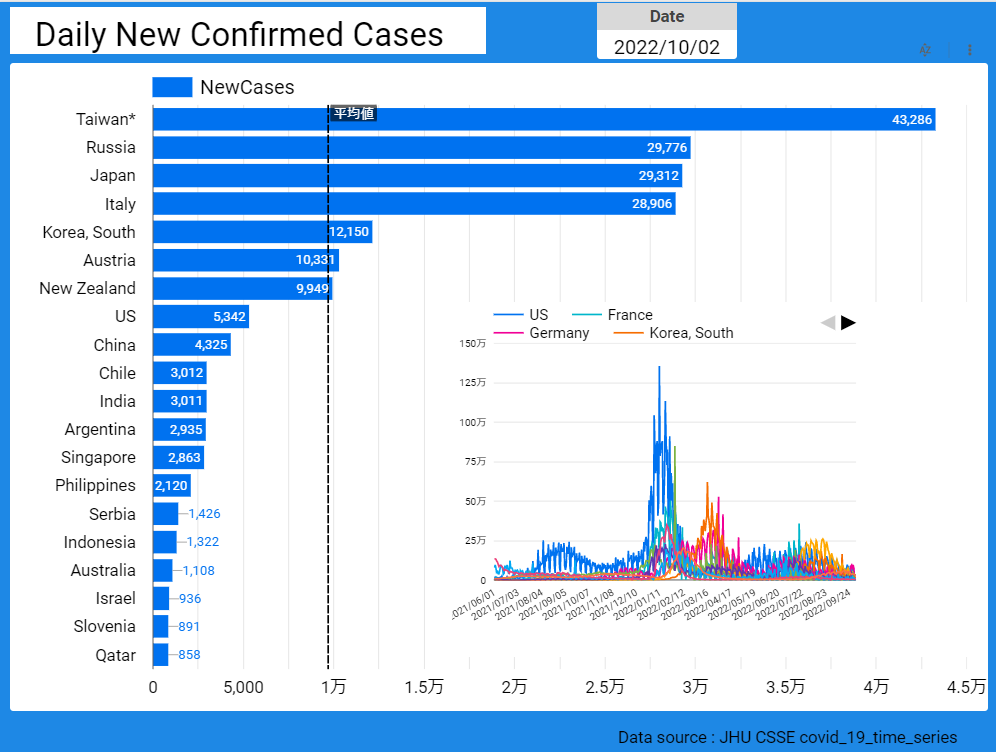
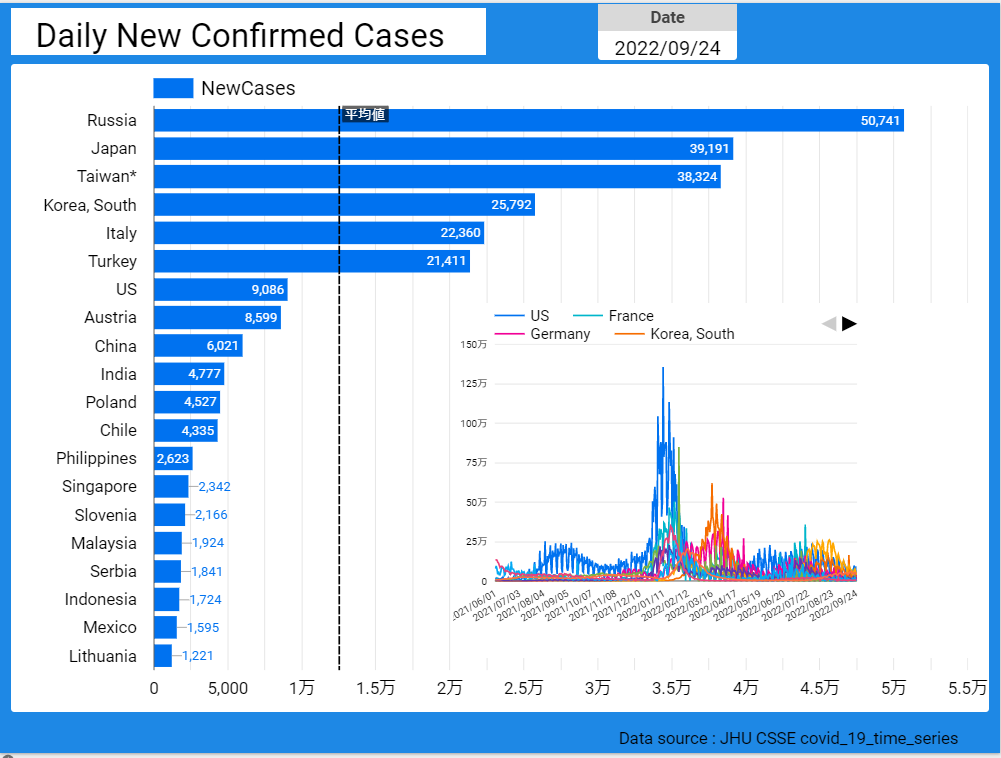
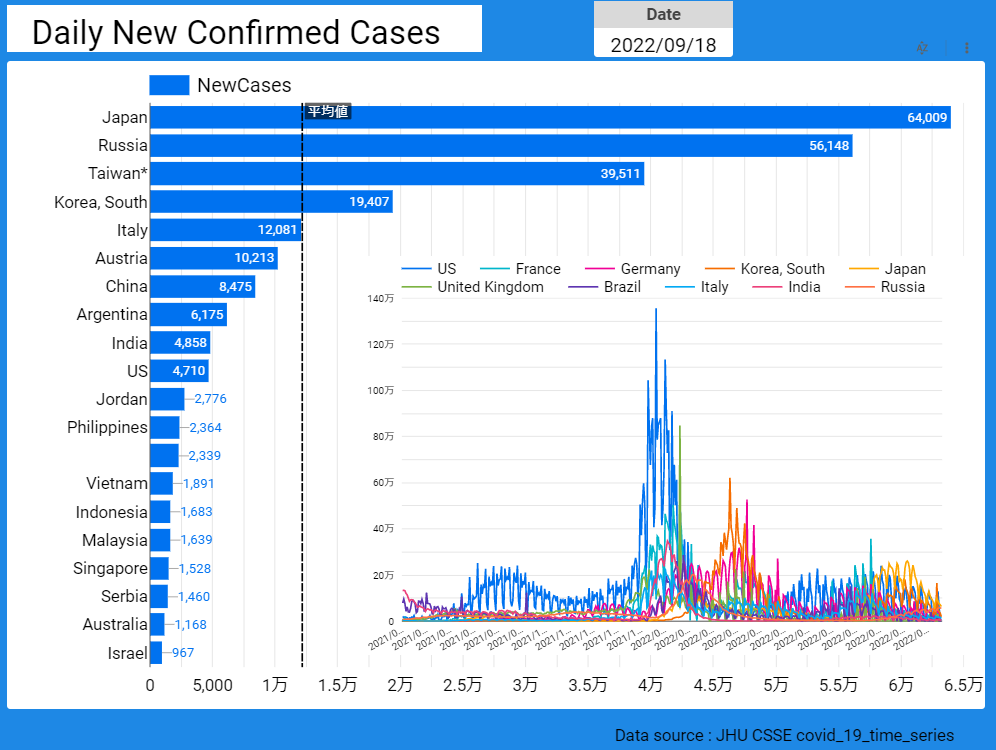
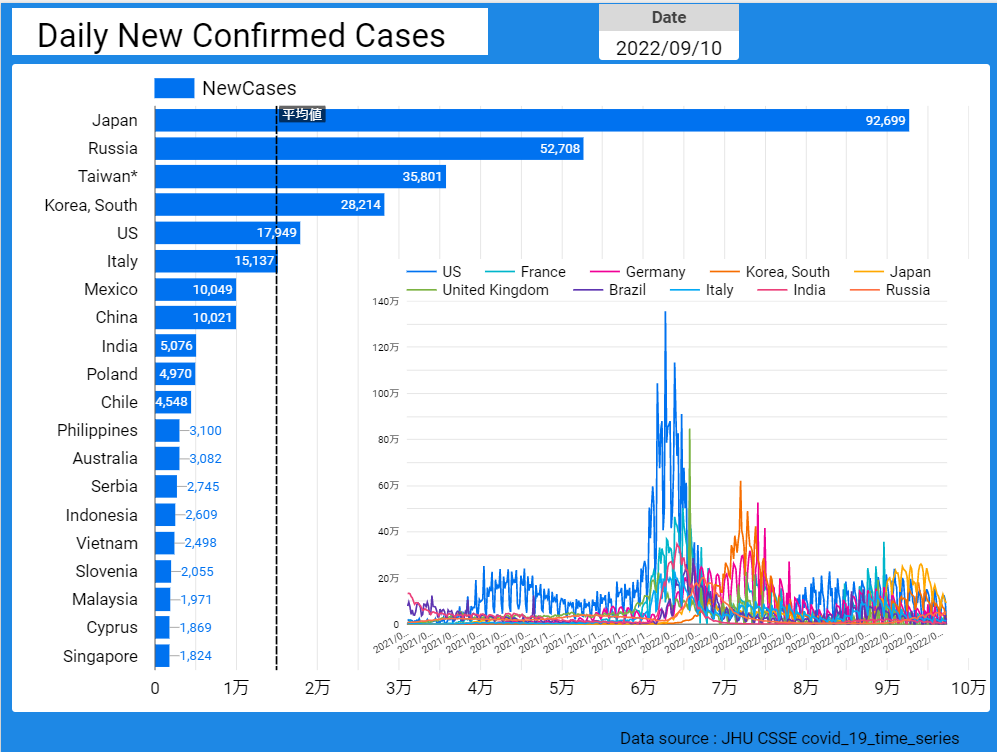
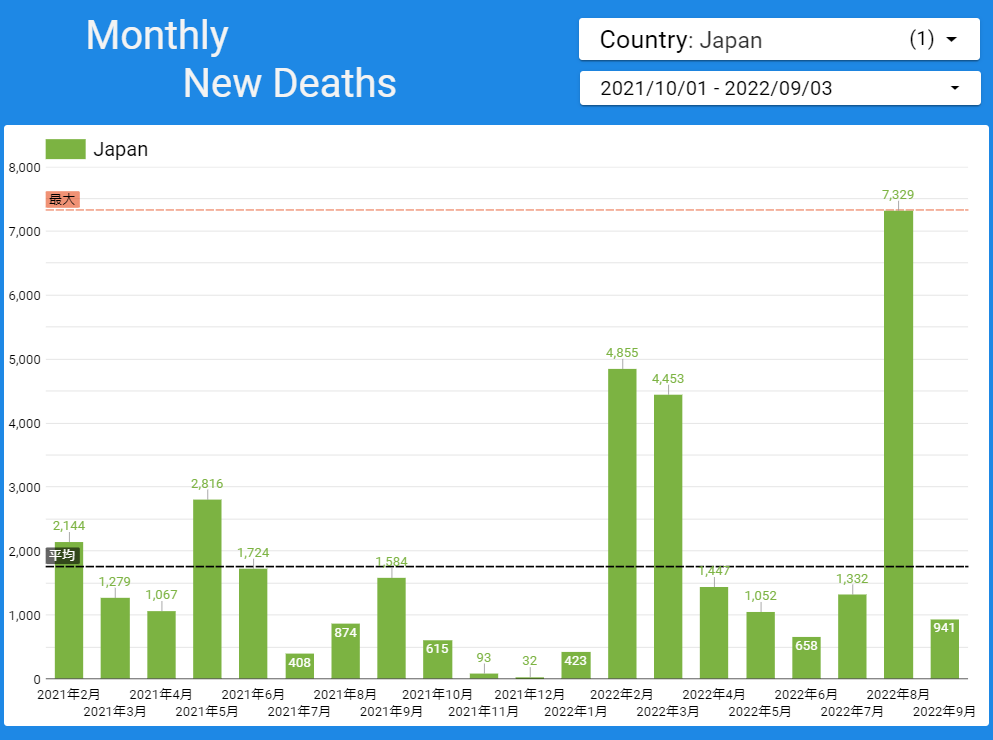
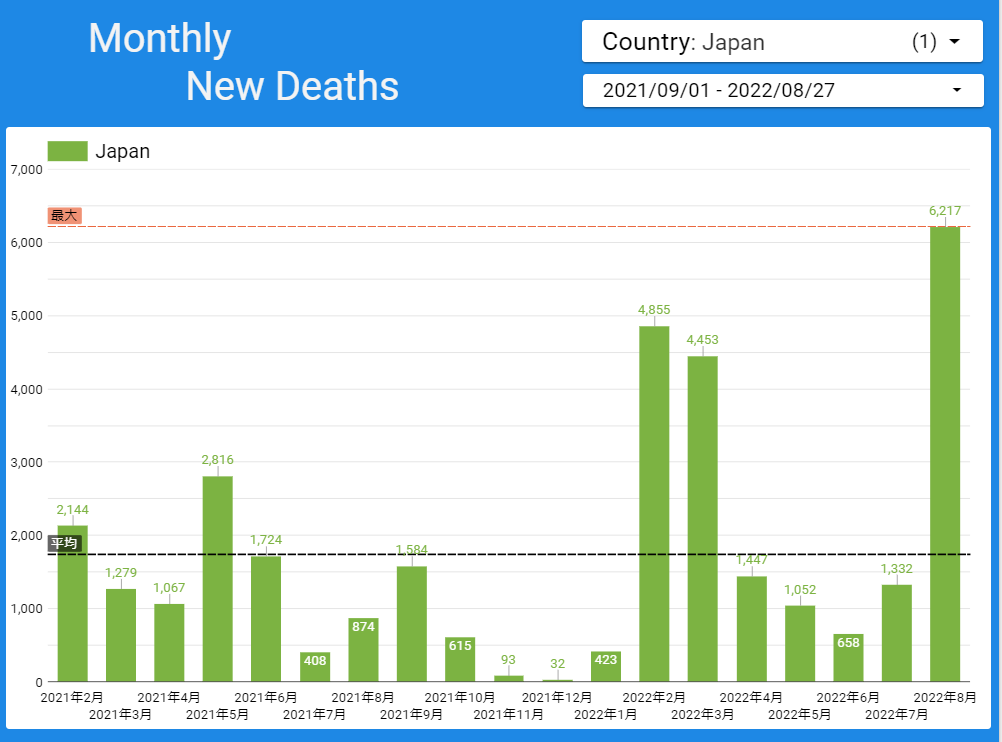
【データ前処理】標準化死亡比のデータの可視化に向けて:R言語での政府統計の前処理の例<その2>
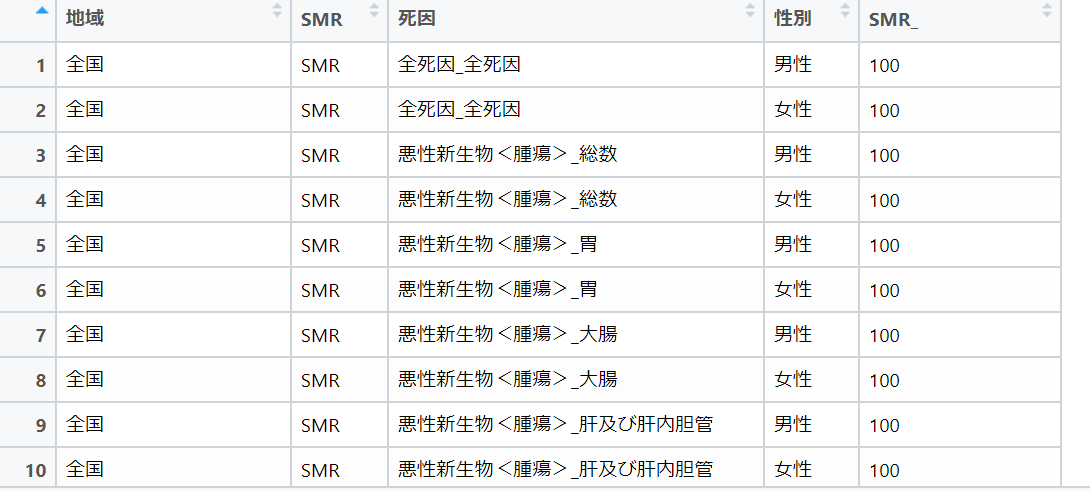
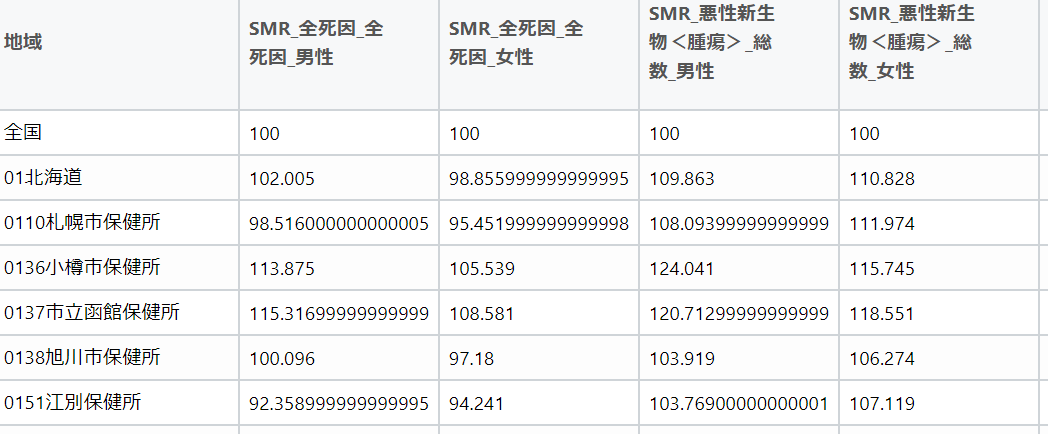
前回の投稿から、スクリプトの修正を行い、データを縦持ち(ロング型)に変更するスクリプトを追加しました。下記のスクリプトがデータを縦持ちにする処理です。1行ごとにデータの説明項目と数値項目が記述されているデータ形式にすることで、BIツールなどで利用しやすくなります。df_smr1 <- df_smr %>% pivot_longer(cols = starts_with("SMR"),names_sep= "_",names_to = c("SMR","死因1","死因2","性別"),values_to = "SMR_")↓この形式のデータに整形すれば、データポータルに読み込むまであともう少しです。地域名が「01北海道」のように「数字+地域名」となっているので、数字と地域名に分ける処理する必要があります。数字のコードと地域名の文字列はあらかじめ2列に分割しておいてもらいたいものですが、よくわからないデータの仕様です。下記のスクリプトで、地域の列の数字+地域名から数字を抜き出して別の列を作成し、抜き出した後で地域の列の数字を削除しました。分割処理がスマートですが、方法が不明だったため、とりあえず単純な処理の組み合わせで対応しています。後で、正規表現を使っで数字と文字を表して分割処理する方法を調べてみようと思います。df_smr3 <- mutate(df_smr2,str_extract_all(df_smr2$"地域", "[0-9.]+"))df_smr4 <- rename(df_smr3,"地域No"= 6)df_smr4$"地域" <- str_replace_all(df_smr4$"地域" ,"[0-9.]+","")<R言語のスクリプト例>df_temp_smr <- read_excel("hyo5_h2529.xlsx",col_names = FALSE,skip = 5,n_max = 3) df_temp_smrview(df_temp_smr)df_temp_smr0 <- df_temp_smr %>% fill(everything()) temp_colname <- tibble(a1=as.character(df_temp_smr0[1,]),a2=as.character(df_temp_smr0[2,]),a3=as.character(df_temp_smr0[3,]),) %>% mutate(SMR = "SMR") %>% select(SMR,everything()) view(temp_colname)colname <- fill(temp_colname,everything()) %>% unite(col = "name",everything()) %>% .$namecolname <- str_replace_all(colname," ","")colname <- str_replace_all(colname," ","")colname <- str_replace_all(colname," ","") colname <- c("地域",colname)view(colname)df_smr <- read_excel("hyo5_h2529.xlsx",col_names = colname,skip = 8) view(df_smr)df_smr1 <- df_smr %>% pivot_longer(cols = starts_with("SMR"),names_sep= "_",names_to = c("SMR","死因1","死因2","性別"),values_to = "SMR_")df_smr2 <- df_smr1 %>% unite(col = "死因","死因1","死因2" )view(df_smr2)df_smr3 <- mutate(df_smr2,str_extract_all(df_smr2$"地域", "[0-9.]+"))df_smr4 <- rename(df_smr3,"地域No"= 6)df_smr4$"地域" <- str_replace_all(df_smr4$"地域" ,"[0-9.]+","")view(df_smr4)