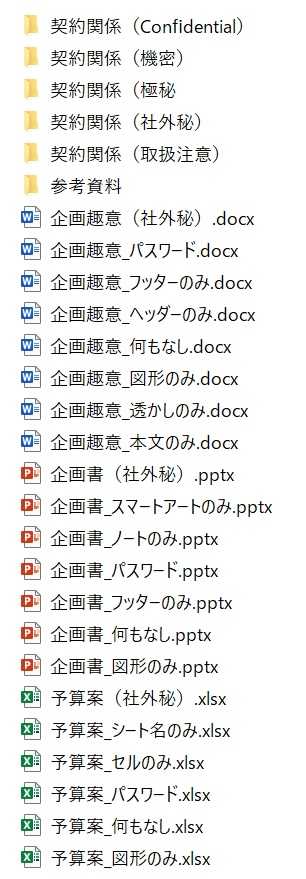
「Pythonで自動化」(前編) その1
久しぶりに、Pythonの勉強を再開しました。テキストは、少し古いのですが、『日経ソフトウエア』2020年5月号「特集1 Pythonで自動化」(p.006-p.031)「機密書類」自動振り分けプログラム(前編)を使いました。コーディングに3、4日、デバッグに5、6日かかりました。検証用のデータを作り、動かしましたが、大体動いたと思います。元々のリストにはない「print」文は、筆者のデバッグのために挿入したものです。また、関数の順番は、筆者が、リストにつけられた番号順に並べ直しています。記号「#」は、以降がコメントとして扱われます。色々勉強になりましたが、「any関数」は、まだ消化できていません。以下、コーディングリストです。print('Start')# 2021/05/01 作成開始 2021/05/14 更新## 「日経ソフトウエア」2020.05# 『特集1 Pythonで自動化』p.006-p.031# 「機密書類」自動振り分けプログラム(前編)## 開発環境の構築 p.006-p.007# 前提 OS:Windows10 Home 64bit# Exel、Word、Powerpointは、Office365の最新版(2020年1月時点)## ①Pythonの開発環境は、「Anaconda」で構築。## 参考URL https://www.python.jp/install/anaconda/windows/install.html## Pythonのバージョン:3.10(2021/05/07時点) # Pythonのコーディングは、「Jupiter Notebook」で行う。## ②必要な外部ライブリを追加 p.007# OpenPyXL :Exelの操作# python-docx:Wordの操作# python-pptx:Powerpointの操作 # pywin32 :ExelとWordの操作# # python-docxとpython-pptxは、追加でインストールする必要がある。# [スタートメニュー]→[Anaconda3] →[Anaconda Prompt]で次のコマンドを入力して、インストールする。# # conda install -c conda-forge python-docx# conda install -c conda-forge python-pptx ## 「機密書類」自動振り分けプログラム# ■機能概要# 「社外秘」などの指定した「キーワード」を含むファイルやフォルダー(ディレクトリ)を自動で判定し、抽出して移動。# 判定はフォルダー名やファイル名およびファイルの中身のテキストで実施。# ■対象# ・フォルダー # ・ファイル3種類 Exel(.xlsx)、Word(.docx)、PowerPoint(.pptx)# ■使い方# 1.プログラムを実行# 2.書類フォルダーを選択# 3.移動先フォルダーを選択# 4.判定と移動が実行される# ■キーワード# ・複数のキーワードを指定可能。コード内にリスト形式で直接記述する。# ■種類別の判定ポイント# ▼共通# ・フィル名 # ・フォルダー名(中に含まれるファイルやフォルダーは名前等に関係なく丸ごと移動)# ▼Exelファイル# セル/ワークシート名/図形(※グラフ、コメント、SmartArtは割愛)# ▼Wordファイル# 本文/ヘッダーとフッター/図形/透かし(※グラフ、表、SmartArtは割愛)# ▼PowerPointファイル# 図形や本文/SmartArt/フッター/ノート# (※図形はタイトルや箇条書きなどのプレースホルダ、テキストボックスも含む。グラフ、表は割愛。ヘッダーは元々ない。)# ■備考# ・判定時はアルファベットの大文字小文字を区別。 # ・パスワードロックなどで開けなかったファイルは、判定・移動は行わない。 # 最後に文言「開けなかったファイル」に続けて、ファイル名(絶対パス付)の一覧を出力。# ・移動先に同名のフォルダー/ファイルが既にあるケースには未対応(エラーで処理を中断する)。 ## ■注# ・元々のリストにない「print」文は、筆者のデバッグのために挿入したもの。# ・関数の順番は、筆者がリストにつけられた番号順に並べ直している。## (メインの処理は[1]から)##print('[0-1]モジュールのインポート')#import sysimport osimport shutilimport zipfileimport globimport pprint#print('[0-2]外部ライブラリのインポート')#import tkinter # Tkinter は Python からGUIを構築・操作するための標準ライブラリ(ウィジェット・ツールキット)import tkinter.filedialog # Tkinter だけでは、環境によってはエラーになることがあるので、その対策import openpyxl # Exelの操作用の外部ライブラリ、Anacondaに最初から入っている。import docx # Wordの操作用の外部ライブラリimport pptx # PowerPointの操作用の外部ライブラリimport win32com.client # ExelとWordの操作用の外部ライブラリ、Anacondaに最初から入っている。#print(' 13個の関数の定義')##print('[2]in_text関数')## ・「in_text関数」の機能は、引数「text」に指定した文字列の中に、# (1-1)のリスト「keywords」の語句のいずれか1つでも含まれていない# かを判定。# ・判定は部分一致で行う。# ・複数あるキーワードのいずれか1つでも含まれている場合、「True」を、# 含まれていない場合、「False」を返す。#def in_text(text): if (type(text) == str and any((keyword in text) for keyword in keywords)): return True return Falseprint('[3]in_docx_shapes関数')def in_xlsx(file_path): try: wb = openpyxl.load_workbook(file_path, data_only=True) except: unsupported_files.append(file_path) return False if (in_xlsx_sheetnames(wb) or in_xlsx_cells(wb) or in_xlsx_shapes(file_path)): return True return Falseprint('[4]in_xlsx_sheetnames関数')def in_xlsx_sheetnames(wb): for sheetname in wb.sheetnames: if in_text(sheetname): return True return Falseprint('[5]in_xlsx_cells関数')def in_xlsx_cells(wb): for ws in wb.worksheets: for row in ws.values: for cell in row: if in_text(cell): return True return Falseprint('[6]in_xlsx_shapes関数')def in_xlsx_shapes(file_path): try: wb = excelApp.Workbooks.Open(file_path) except: unsupported_files.append(file_path) return True for ws in wb.Worksheets: for shape in ws.Shapes: if not shape.TextFrame2.HasText: continue shape_text = shape.TextFrame.Characters().Text if in_text(shape_text): wb.Close() return True wb.Close() return Falseprint('[7]in_docx関数')def in_docx(file_path): try: # (7-1)[7]in_docx関数 doc = docx.Document(file_path) except: unsupported_files.append(file_path) return False # (7-2)[7]in_docx関数 if (in_docx_paragraph(doc) or in_docx_headerfooter(doc) or in_docx_shapes(file_path)): return True # (7-3)[7]in_docx関数 with zipfile.ZipFile(file_path) as zf: # (7-4)[7]in_docx関数 zf.extractall(DIR_TMP) # (7-5)[7]in_docx関数 if in_msoffice_xml('header*.xml'): # (7-6)[7]in_docx関数 shutil.rmtree(DIR_TMP) return True shutil.rmtree(DIR_TMP) return False print('[8]in_docx_paragraph関数') def in_docx_paragraph(doc): # (8-1) [8]in_docx_paragraph関数 for paragraph in doc.paragraphs: # (8-2) [8]in_docx_paragraph関数 if in_text(paragraph.text): return True return Falseprint('[9]in_docx_headerfooter関数')def in_docx_headerfooter(doc): for section in doc.sections: for header_paragraph in section.header.paragraphs: if in_text(header_paragraph.text): return True for footer_paragraph in section.footer.paragraphs: if in_text(footer_paragraph.text): return True return Falseprint('[10]in_docx_shapes関数')def in_docx_shapes(file_path): try: doc = wordApp.Documents.Open(file_path) except: unsupported_files.append(file_path) return False for shape in doc.shapes: if not shape.TextFrame.HasText: continue shape_text = shape.TextFrame.TextRange.Text if in_text(shape_text) : doc.Close() return True doc.Close() return Falseprint('[11]in_msoffice_xml関数')def in_msoffice_xml(target): target_path = os.path.join(DIR_TMP, '**', target) for xmlfile in glob.glob(target_path, recursive=True): with open(xmlfile, encoding='utf-8') as f: xmlcontents = f.read() if in_text(xmlcontents): return True return Falseprint('[12]in_pptx関数')def in_pptx(file_path): try: prs = pptx.Presentation(file_path) except: unsupported_files.append(file_path) return False if (in_pptx_shapes(prs) or in_pptx_note(prs) ): return True with zipfile.ZipFile(file_path) as zf: zf.extractall(DIR_TMP) if in_msoffice_xml('data*.xml') : shutil.rmtree(DIR_TMP) return True shutil.rmtree(DIR_TMP) return Falseprint('[13]in_pptx_shapes関数')def in_pptx_shapes(prs): for slide in prs.slides: for shape in slide.shapes: if not shape.has_text_frame: continue for paragraph in shape.text_frame.paragraphs: if in_text(paragraph.text): return True return Falseprint('[14]in_pptx_note関数')def in_pptx_note(prs): for slide in prs.slides: note_text = slide.notes_slide.notes_text_frame.text if in_text(note_text): return True return False###############################################################################################################################print('[1]ここからメインの処理')################################################################################################################################(1-1)キーワードのリストを用意するコードkeywords = ['社外秘', '機密', '取扱注意', '極秘', 'Confidential'] #(1-2)DIR_TMP = 'tmp'#(1-3)リスト「unsupported_files」を初期化する処理# このリストには、開けなかったファイル名をその都度追加で格納unsupported_files = [] #(1-4)pywin32で、ExelとWordを操作するための準備となる処理# pywin32は、「[0-2]外部ライブラリのインポート」でインポートしている。excelApp = win32com.client.Dispatch('Excel.Application') wordApp = win32com.client.Dispatch('Word.Application') #(1-5)書類フォルダー選択用のダイアログボックスを生成する処理rt = tkinter.Tk() rt.withdraw()msg = '書類のフォルダーを選択してください。'document_dir_path = tkinter.filedialog.askdirectory(title=msg)#(1-6)ダイアログボックスで[キャンセル]ボタンがクリックされた場合の処理if not document_dir_path: print('フォルダーを選んでください。') sys.exit() # 移動先フォルダーをダイアログボックスで選択する処理msg = '移動先のフォルダーを選択してください。'output_dir_path = tkinter.filedialog.askdirectory(title=msg)if not output_dir_path: print('フォルダーを選んでください。') sys.exit()#(1-7)本サンプルコードの柱となる処理for root, dirs, files in os.walk(document_dir_path): #(1-8) for dir in dirs: #(1-9) dir_path = os.path.join(root, dir) print('Taget dir:', dir_path) #(1-10) if in_text(dir): #(1-11) shutil.move(dir_path, output_dir_path) print('moved!') #(1-12) for file in files: file_path = os.path.join(root, file) print('Taget file:', file_path) #(1-13) if in_text(file): shutil.move(file_path, output_dir_path) print('moved!') #(1-14) continue #(1-15) ext = os.path.splitext(file)[1] #(1-16) if ((ext == '.xlsx' and in_xlsx(file_path)) or (ext == '.docx' and in_docx(file_path)) or (ext == '.pptx' and in_pptx(file_path))): shutil.move(file_path, output_dir_path) print('moved!') #(1-17)print('\n\n開けなかったファイル')pprint.pprint(unsupported_files)excelApp.Quit()wordApp.Quit()