|
|
|
|
2022.10.31
カテゴリ:データ分析
標準化死亡比(SMR:Standardized Mortality Ratio)という指標があり、死因別に各市区町村が全国を100とした場合に、その市区町村での死亡数が多い傾向にあるのか、少ない傾向にあるのかを知ることができます。 https://maeshori-r.connpass.com/event/219249/今回は、上記の「まず、列名情報だけを整える」という方法とR言語のスクリプトをそのままマネさせていただき、政府の公開データ「標準化死亡比,三大死因・性・都道府県・保健所・市区町村別」の表の前処理をしてみました。 データポータルで地図を作成するのが目標ですが、とりあえず、表の列名の整備までがほぼできた感じです。前処理をした列名でデータを読み込むことができました。 この程度の処理は、もちろんExcelのシート上で手作業で行う場合が多いと思いますが、R言語のスクリプトで処理できるようにしておけば、より複雑な表の場合や同じ処理を繰り返す必要がある場合に役立ちます。 また、この方法であれば、元のデータファイル自体を直接変更せずに処理することが可能であるため、間違ってデータの入っているセルを消したり、上書きしたりといった手作業でのケアレスミスを防ぐことができます。 ※追記:文字列中の空白が削除できていませんでしたので、下記のスクリプトに修正しました。 colname <- str_replace_all(colname," ","") 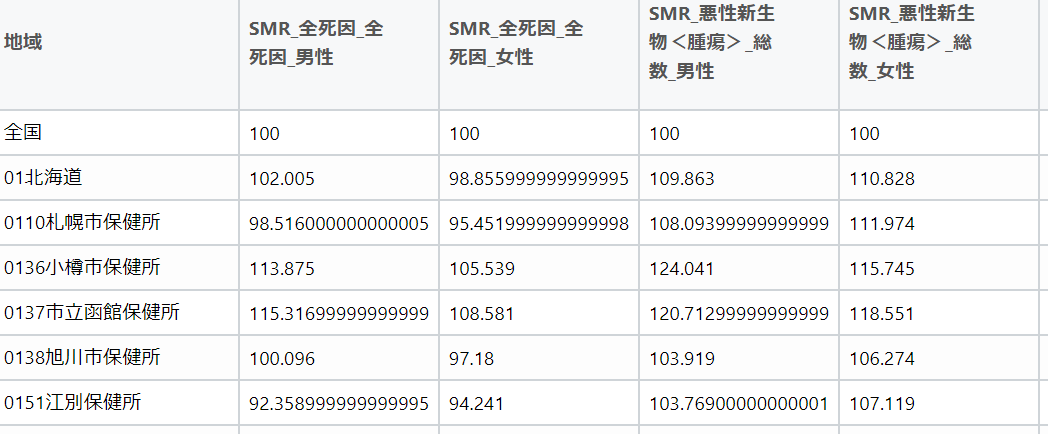 【R言語による前処理の例】 df_temp_smr <- read_excel("hyo5_h2529.xlsx",col_names = FALSE,skip = 5,n_max = 3) df_temp_smr df_temp_smr0 <- df_temp_smr %>% fill(everything()) temp_colname <- tibble( a1=as.character(df_temp_smr0[1,]), a2=as.character(df_temp_smr0[2,]), a3=as.character(df_temp_smr0[3,]), ) %>% mutate(SMR = "SMR") %>% select(SMR,everything()) colname <- fill(temp_colname,everything()) %>% unite(col = "name",everything()) %>% .$name colname <- str_replace_all(colname," ","") colname <- c("地域",colname) df_smr <- read_excel("hyo5_h2529.xlsx",col_names = colname,skip = 8) view(df_smr) ============================= 下記のURLのページでは、Pythonによるデータ処理後、データポータルで市区町村別のSMRについて可視化した例が紹介されています。https://zenn.dev/kaorumori/articles/403ea0f2414b70 お気に入りの記事を「いいね!」で応援しよう
Last updated
2022.11.01 07:42:33
コメント(0) | コメントを書く
[データ分析] カテゴリの最新記事
|
|



