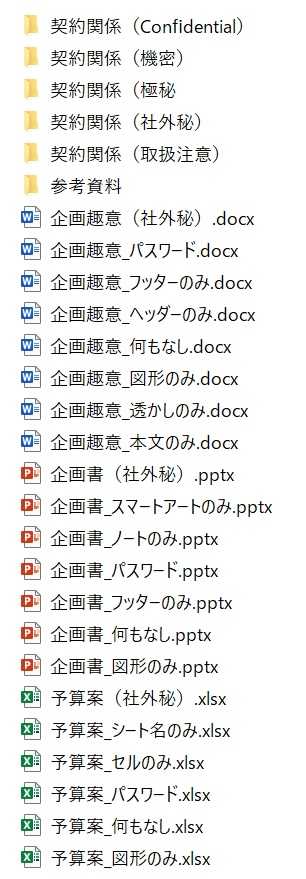
「Pythonで自動化」(後編) その11 リスト5完成版
ようやく完成版のリスト5がちゃんと動くようになりました。サンプルプログラムのリスト5は、次のとおりです。# リスト5 完成版のサンプルプログラム## 2021/05/17 作成開始 2021/06/03 更新## 「日経ソフトウエア」2020.07# 『特集5 Pythonで自動化』p.066-p.088# 「機密書類」自動振り分けプログラム(後編)## ■機能概要# 後編では、前編のプログラムに、以下の<A>、<B>の機能を追加。# 簡易的なOCRを行い、画像上の文字を認識する機能を実装する。# サポートする画像の形式は、JPEGとPNGのみ。## <A>対象ファイルにPDFファイルを追加する。# PDFファイルの本文とヘッダー、フッター、図形のテキストで判定。# しおり、透かし、コメントでの判定は割愛。# <B>Exel/Word/PowerPoint/PDFファイル内の画像で判定。# 「社外秘」などが、スタンプのような画像(テキストデータではなく) # で埋め込まれているファイルを抽出する機能。## ■流れ# PDFminerインストール→PDFテキストを抽出→PyPDFインストール# →PDF画像抽出→OCR関係インストール→完成版サンプルプログラム## ■PDFminer.sixのインストール# [スタートメニュー」などから、「Anaconda Prompt」を立ち上げ、次のコマンドを実行する。## conda install -c conda-forge pdfminer### (メインの処理は[1]から)##print('[0-1]モジュールのインポート')#import sysimport osimport shutilimport zipfileimport globimport pprintimport ioprint('[0-2]外部ライブラリのインポート')import tkinter # Tkinter は Python からGUIを構築・操作するための標準ライブラリ(ウィジェット・ツールキット)import tkinter.filedialog # Tkinter だけでは、環境によってはエラーになることがあるので、その対策import openpyxl # Exelの操作用の外部ライブラリ、Anacondaに最初から入っている。import docx # Wordの操作用の外部ライブラリimport pptx # PowerPointの操作用の外部ライブラリimport win32com.client # ExelとWordの操作用の外部ライブラリ、Anacondaに最初から入っている。from PIL import Imageimport pyocrfrom pdfminer.pdfinterp import PDFResourceManagerfrom pdfminer.converter import TextConverterfrom pdfminer.pdfinterp import PDFPageInterpreterfrom pdfminer.pdfpage import PDFPagefrom pdfminer.layout import LAParamsfrom PyPDF2 import PdfFileReader#print(' 17個の関数の定義')##print('[2]in_text関数 抽出したテキストにキーワードが含まれるかを判定する関数')## ・「in_text関数」の機能は、引数「text」に指定した文字列の中に、# (1-1)のリスト「keywords」の語句のいずれか1つでも含まれていない# かを判定。# ・判定は部分一致で行う。# ・複数あるキーワードのいずれか1つでも含まれている場合、「True」を、# 含まれていない場合、「False」を返す。#def in_text(text): if (type(text) == str and any((keyword in text) for keyword in keywords)): return True return Falseprint('[3]in_xlsx関数 Excelファイルを判定する関数')#def in_xlsx(file_path): try: wb = openpyxl.load_workbook(file_path, data_only=True) except: unsupported_files.append(file_path) return False if (in_xlsx_sheetnames(wb) or in_xlsx_cells(wb) or in_xlsx_shapes(file_path)): return True with zipfile.ZipFile(file_path) as zf: zf.extractall(DIR_TMP) if in_msoffice_img('image*.*'): shutil.rmtree(DIR_TMP) return True shutil.rmtree(DIR_TMP) return Falseprint('[4]in_xlsx_sheetnames関数 ワークシート名で判定する関数')## ・「in_xlsx_sheetnames関数」の機能は、引数「sheetname」に指定した文字列の中に、# (1-1)のリスト「keywords」の語句のいずれか1つでも含まれていない# かを判定。# ・判定は部分一致で行う。# ・複数あるキーワードのいずれか1つでも含まれている場合、「True」を、# 含まれていない場合、「False」を返す。#def in_xlsx_sheetnames(wb): for sheetname in wb.sheetnames: if in_text(sheetname): return True return Falseprint('[5]in_xlsx_cells関数 セルの値で判定する関数')#def in_xlsx_cells(wb): for ws in wb.worksheets: for row in ws.values: for cell in row: if in_text(cell): return True return Falseprint('[6]in_xlsx_shapes関数 図形で判定する関数')#def in_xlsx_shapes(file_path): try: wb = excelApp.Workbooks.Open(file_path) except: unsupported_files.append(file_path) return True for ws in wb.Worksheets: for shape in ws.Shapes: if not shape.TextFrame2.HasText: continue shape_text = shape.TextFrame.Characters().Text if in_text(shape_text): wb.Close() return True wb.Close() return Falseprint('[7]in_docx関数 Wordファイルを判定する関数')#def in_docx(file_path): try: doc = docx.Document(file_path) except: unsupported_files.append(file_path) return False if (in_docx_paragraph(doc) or in_docx_headerfooter(doc) or in_docx_shapes(file_path)): return True with zipfile.ZipFile(file_path) as zf: zf.extractall(DIR_TMP) if (in_msoffice_xml('header*.xml') or in_msoffice_img('image*.*')): shutil.rmtree(DIR_TMP) return True shutil.rmtree(DIR_TMP) return False print('[8]in_docx_paragraph関数 本文で判定する関数') def in_docx_paragraph(doc): for paragraph in doc.paragraphs: if in_text(paragraph.text): return True return Falseprint('[9]in_docx_headerfooter関数 ヘッダーとフッターで判定する関数')def in_docx_headerfooter(doc): for section in doc.sections: for header_paragraph in section.header.paragraphs: if in_text(header_paragraph.text): return True for footer_paragraph in section.footer.paragraphs: if in_text(footer_paragraph.text): return True return Falseprint('[10]in_docx_shapes関数 図形で判定する関数')#def in_docx_shapes(file_path): try: doc = wordApp.Documents.Open(file_path) except: unsupported_files.append(file_path) return False for shape in doc.shapes: if not shape.TextFrame.HasText: continue shape_text = shape.TextFrame.TextRange.Text if in_text(shape_text) : doc.Close() return True doc.Close() return Falseprint('[11]in_msoffice_xml関数 透かし、SmartArtで判定する関数')#def in_msoffice_xml(target): target_path = os.path.join(DIR_TMP, '**', target) for xmlfile in glob.glob(target_path, recursive=True): with open(xmlfile, encoding='utf-8') as f: xmlcontents = f.read() if in_text(xmlcontents): return True return Falseprint('[12]in_pptx関数 PowerPointファイルを判定する関数')#def in_pptx(file_path): try: prs = pptx.Presentation(file_path) except: unsupported_files.append(file_path) return False if (in_pptx_shapes(prs) or in_pptx_note(prs) ): return True with zipfile.ZipFile(file_path) as zf: zf.extractall(DIR_TMP) if (in_msoffice_xml('data*.xml') or in_msoffice_img('image*.*')): shutil.rmtree(DIR_TMP) return True shutil.rmtree(DIR_TMP) return Falseprint('[13]in_pptx_shapes関数 図形や本文で判定する関数')#def in_pptx_shapes(prs): for slide in prs.slides: for shape in slide.shapes: if not shape.has_text_frame: continue for paragraph in shape.text_frame.paragraphs: if in_text(paragraph.text): return True return Falseprint('[14]in_pptx_note関数 ノートで判定する関数')#def in_pptx_note(prs): for slide in prs.slides: note_text = slide.notes_slide.notes_text_frame.text if in_text(note_text): return True return Falseprint('[15]in_pdf関数 PDFで判定する関数')#def in_pdf(file_path): try: with open(file_path, 'rb') as fp: if (in_pdf_text(fp) or in_pdf_img(fp)): return True except: unsupported_files.append(file_path) return False return Falseprint('[16]in_pdf_text関数 PDFのテキストで判定する関数')#def in_pdf_text(fp): # リスト1 # # PDFファイルからpdfminerでテキストを抽出するテスト # 「日経ソフトウエア」2020.07 # 『特集5 Pythonで自動化』p.066~p.069 # #(1)ライブラリの読み込み #import io #from pdfminer.pdfinterp import PDFResourceManager #from pdfminer.converter import TextConverter #from pdfminer.pdfinterp import PDFPageInterpreter #from pdfminer.pdfpage import PDFPage #from pdfminer.layout import LAParams #(2)必要なオブジェクトの生成 stdout.truncate(0) rscmgr = PDFResourceManager() lprms = LAParams() device = TextConverter(rscmgr, stdout, laparams=lprms) intprtr = PDFPageInterpreter(rscmgr, device) #(3)目的のPDFファイルを開く処理 # PDFファイルを、第2引数の「rb」で読み取り専用、バイナリーモードで開く。 # 「r」は読み込み用、「b」はバイナリーを意味する。 #fp = open('PDFtest1.pdf', 'rb') #(4)実際にテキストを抽出している処理 for page in PDFPage.get_pages(fp): #(5)変数「page」のページの中からテキストを抽出する処理の本体 # 実行すると変数「page」のページ内のテキストがテキストストリーム(変数「stdout」)に出力される。 intprtr.process_page(page) #(6)テキストストリームの内容を取得する処理 # テキストストリームの内容が戻り値として得られるので、変数「text」に格納 pdf_text = stdout.getvalue() #(7)テキストストリーム、TextConverterオブジェクト、PDFファイルを閉じる処理 # 閉じ忘れると次回実行時にエラーが出るので、注意! #stdout.close() device.close() #fp.close() if in_text(pdf_text): return True return Falseprint('[17]in_pdf_img関数 PDFの画像で判定する関数')#def in_pdf_img(fp): print('[17-3]必要なオブジェクトの生成') reader = PdfFileReader(fp) pgnum = reader.getNumPages() print('[17-4]実際の処理') for i in range(pgnum): pg = reader.getPage(i) if '/XObject' in pg['/Resources']: xobjs = pg['/Resources']['/XObject'] print('[17-7]') for key, obj in xobjs.items(): item = obj.getObject() if item['/Subtype'] == '/Image': #[17-8-1] if item['/Filter'] == '/FlateDecode': #[17-8-2] size = (item['/Width'], item['/Height']) data = item.getData() img = Image.frombytes('RGB', size, data) elif item['/Filter'] == '/DCTDecode': data = item.getData() img = Image.open(io.BytesIO(data)) else: break #実際に文字認識処理を行っているコード img_text = tool.image_to_string( img, lang ='jpn+eng', builder = pyocr.builders.TextBuilder() ) if in_text(img_text): return True return False print('[18]in_msoffice_img関数 Excel/Word/PowerPointの画像で判定する関数')#def in_msoffice_img(target): # 本文のままのコードでは、(1)でOCRエンジンのオブジェクトが取得できなかったため、 # # https://tsukimitech.com/pyocr-get_available_tools/ # # の記事を参考にして、次のコードを追加。 #pyocr.tesseract.TESSERACT_CMD = r'C:\\Program Files\\Tesseract-OCR\\tesseract.exe' target_path = os.path.join(DIR_TMP, '*.*', target) img_files = glob.glob(target_path, recursive=True) for img_file in img_files: #(3)実際に文字認識処理を行っているコード img_text = tool.image_to_string( Image.open(img_file), lang = 'jpn+eng', builder = pyocr.builders.TextBuilder() ) if in_text(img_text): return True return False###############################################################################################################################print('[1]ここからメインの処理')###############################################################################################################################print('[1-1]キーワードのリストを用意するコード')keywords = ['社外秘', '機密', '取扱注意', '極秘', 'Confidential'] #[1-2]DIR_TMP = 'tmp'#[1-3]リスト「unsupported_files」を初期化する処理# このリストには、開けなかったファイル名をその都度追加で格納unsupported_files = [] #[1-4]pywin32で、ExelとWordを操作するための準備となる処理# pywin32は、「[0-2]外部ライブラリのインポート」でインポートしている。excelApp = win32com.client.Dispatch('Excel.Application') wordApp = win32com.client.Dispatch('Word.Application')#(1-1)stdout = io.StringIO()#(1-2)# 本文のままのコードでは、(1)でOCRエンジンのオブジェクトが取得できなかったため、## https://tsukimitech.com/pyocr-get_available_tools/## の記事を参考にして、次のコードを追加。pyocr.tesseract.TESSERACT_CMD = r'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'#(1-2-1)OCRエンジンのオブジェクトを取得して、リスト変数「tools」に格納する処理tools = pyocr.get_available_tools()if len(tools) == 0: print("OCRツールが見つかりませんでした") sys.exit(1)#(1-2-2)実際に使うOCRエンジンオブジェクトを取り出して、変数「tool」に格納する処理tool = tools[0]#[1-5]書類フォルダー選択用のダイアログボックスを生成する処理rt = tkinter.Tk() rt.withdraw()msg = '書類のフォルダーを選択してください。'document_dir_path = tkinter.filedialog.askdirectory(title=msg)#[1-6]ダイアログボックスで[キャンセル]ボタンがクリックされた場合の処理if not document_dir_path: print('フォルダーを選んでください。') sys.exit() # 移動先フォルダーをダイアログボックスで選択する処理msg = '移動先のフォルダーを選択してください。'output_dir_path = tkinter.filedialog.askdirectory(title=msg)if not output_dir_path: print('フォルダーを選んでください。') sys.exit()print('[1-7]本サンプルコードの柱となる処理')for root, dirs, files in os.walk(document_dir_path): print('[1-8]') for dir in dirs: #[1-9] dir_path = os.path.join(root, dir) print('[1-9]Taget dir:', dir_path) #[1-10] if in_text(dir): #[1-11] shutil.move(dir_path, output_dir_path) print('[1-11]moved!') #[1-12] for file in files: file_path = os.path.join(root, file) print('[1-12]Taget file:', file_path) #[1-13] if in_text(file): shutil.move(file_path, output_dir_path) print('[1-13]moved!') #[1-14] continue #[1-15] ext = os.path.splitext(file)[1] #[1-16] if ((ext == '.xlsx' and in_xlsx(file_path)) or (ext == '.docx' and in_docx(file_path)) or (ext == '.pptx' and in_pptx(file_path)) or (ext == '.pdf' and in_pdf(file_path))): shutil.move(file_path, output_dir_path) print('[1-16]moved!')#[1-17]print('\n\n開けなかったファイル')pprint.pprint(unsupported_files)excelApp.Quit()wordApp.Quit()stdout.close()